
Towards safe clinical conversational artificial intelligence
Where are we now, how did we get here, and how can we get the health system to benefit?

By Neil Graham1,2, Stephen Auger1,2, Ariel Ong3, Gregory Scott1,2
1) Applied Health Intelligence Lab, Department of Brain Sciences, Imperial College London
2) UK Dementia Research Institute Centre for Care Research and Technology, Imperial College London
3) Institute of Ophthalmology, University College London, London, UK
Summary
Breakthroughs in machine learning mean that tools capable of interacting with patients through natural language are now widely available. These tools bring major potential to support healthcare workers in complex tasks such as undertaking consultations, clinical reasoning, and formulating management plans. Despite this promise, outside of lower-risk applications like transcription and summarisation, the potential of conversational clinical artificial intelligence (AI) remains largely unrealised.
Several years after the release of ChatGPT, we still lack a deep understanding of the clinical reasoning capabilities of large language models (LLMs), which perform outstandingly in some domains and entirely inadequately in others. Clinicians and patients should work together to define what constitutes high-quality performance for clinical conversational AI. This requires agreement on general standards for performance, and specific rules governing the clinical content of narrowly defined clinical encounters. This work will enable us to arrive at appropriate safety thresholds, measure and mitigate algorithmic bias, patient privacy, and deploy these technologies fairly within complex healthcare systems.
Here, we review how LLMs work, what is known about their capabilities in healthcare, and outline the steps required to co-produce conversational clinical AI systems with patients that are demonstrably safe, accurate, fair, and empathetic.
Background
There is increasing demand for medical care driven in large part by an ageing population and an expansion in our ability to identify, prevent and treat problems, even as the worldwide shortage of healthcare professionals continues. Even in countries with high levels of wealth, many patients are having to wait excessively to access the right clinician.1 In the case of neurological practice, which includes some of the most common diseases such as headache, traumatic brain injury, and cerebrovascular disease, the UK has amongst the fewest specialists in Europe relative to its population size (1/91,175 people)2.
The mismatch of demand and supply could be mitigated by empowering our highly skilled workforce with digital ‘team mates’. Large language models (LLMs), a type of generative artificial intelligence (AI), which make sophisticated predictions about text, have a wide range of potential healthcare use cases, spanning administration (e.g., clinical coding, transcription, summarisation), image analysis, translation, decision support, and direct patient care.
Clinical conversational AI refers to turn-by-turn clinical dialogue between a patient and a software program (such as a LLM). Such programs have potential to perform a range of healthcare functions, including history taking, reasoning, making diagnoses, formulating management plans, communicating these with patients and following up to establish if these were successful3-5. In recent years there have been major technical advances in model architectures which mean that this is now a genuine possibility (See Box 1).
Conversational clinical AI could be integrated at several points in existing care pathways, including health promotion and prevention, condition-specific triage, pre-appointment review, decision support, chronic disease monitoring, delivery of language-based treatments, and assessing outcomes. Consider the context of long waiting lists for specialist outpatient services: an AI assistant could interactively take a history from a patient awaiting review and summarise it for the clinician, enabling key investigations to be organised in advance of the appointment. The assistant could prepare self-management advice, freeing consultation time to focus on the patient’s concerns.
At the time of writing, LLM-based AI medical tools have been approved in a range of lower-risk contexts, such as transcribing and summarising consultations (so-called ‘ambient voice technologies’ or ‘scribes’, e.g. Heidi, MHRA Class I), administration (e.g. coding; Tandem, EU MDA Class IIa), and research/literature review (e.g. OpenEvidence). Only one product has approval to provide LLM-powered diagnostic clinical decision support (Dr Valmed, EU MDR Class IIb), and none currently have approval to interactively take histories and diagnose.
AI assistants could transform our current model of care, a paradigm which involves gathering a history, undertaking an examination, formulating a management plan and communicating this in accessible language, all during highly time-constrained clinical encounters of no more than 60 minutes in secondary care, and 10-15 minutes in primary care. These constraints inevitably lead to compromises in the quality of care. LLMs could enable clinical conversations with patients which span hours, and in a stop-start manner to suit the patient, during which the model could deeply characterise their history, ideas, concerns and expectations. This would be preferable to the automated questionnaire-based systems sometimes used to capture information before, or following visits (eg. patient reported outcome measures) which, while ideal for research, have limitations in capturing patients experience.6
Generative AI has been rapidly integrated into non-medical consumer products. However, before patients can benefit from LLM-powered medical applications beyond limited cases7, we need to answer pressing questions about how such tools should be developed, tested, and incorporated into health systems. This work must happen rapidly, recognising the strong demand for accessible clinical reasoning support and the risk that patients will turn to unregulated, freely available general-purpose tools and hope for the best.
How do large language models function?
The current generation of LLMs can best be considered ‘next word prediction’ computer programs. Or strictly, next ‘token’ prediction machines, because for reasons of performance and efficiency, models perform better when words are broken up into smaller sub-word chunks, called ‘tokens’. When we run a model (termed ‘inference’), each subsequent token is picked from a probability distribution, based on the model’s learned parameters and its short-term memory (‘context window’), which contains a set of instructions about how to behave (‘system prompt’), the user’s input (‘prompt’) and the conversation so far.
A model’s behaviour is largely determined by its size and training data. During ‘pre-training’, the model iteratively reads across an extremely large corpus of text, masks the next word, and attempts to predict it. Based on its success or failure at each prediction, the model’s billions of weights, learned numerical parameters, are updated (‘backpropagation’, resulting from a ‘loss function’). This process, at scale, may take up to 6 months and cost as much as $5 billion for a large frontier model with >1tn parameters. The raw model then undergoes further adjustments of its weights, in ‘fine-tuning’ to instil the desired behaviours, such as those of a helpful assistant, using paired questions with ideal responses (‘supervised fine tuning’), automated feedback, or human feedback, where responses are annotated by human raters (‘reinforcement learning with human feedback’, RLHF).
What do we know about models’ medical intelligence and skill?
Scaling up the amount of the training data, number of model weights and amount of training compute resource has produced remarkable LLM performance gains8. However, their performance is highly inconsistent across domains, the so-called ‘jagged frontier of intelligence’. Many of these limitations have been surprising, like difficulties in early models answering questions like “How many ‘R’s are there in the word strawberry?” or “Which number is larger, 9.11 or 9.9?”. A tendency to invent information, termed ‘hallucinations’ in the AI community but more accurately thought of as ‘confabulations’,9 has been difficult to fully mitigate.
Understanding a model’s knowledge or ability is surprisingly difficult, and tends to rely on structured experiments, called ‘benchmark’ tests. This reflects our lack of understanding of how information is encoded in a model’s weights, or how interactions between model components produce the behaviour.
LLMs have improved rapidly on multiple choice question sets like the US Medical Licencing Examinations. Open-weight models, those LLMs with publicly available trained parameters have historically lagged behind larger proprietary models but have begun to catch up and are now able to exceed typical human performance on common benchmarks (Figure 1)10. However these tests have limitations, and even small changes to questions, such as adding an “I don’t know” answer option or re-ordering answers, can have significant effects on LLMs’ performance, suggesting that more robust evaluation is needed to truly understand models’ medical knowledge and capabilities.11 Strong potential of LLMs in more complex diagnostic problems was demonstrated in 2024 using NEJM clinical challenges; GPT4 scored 88.7% versus 51.4% for the journal’s readership12.
Figure 1. Performance of large language models on us medical licensing examination multiple choice questions
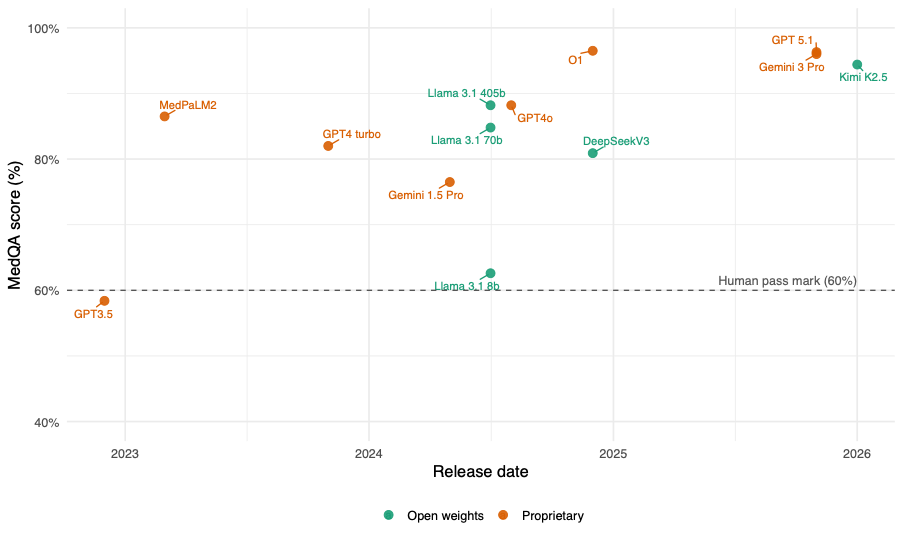
Assessment in settings that more closely reflect real-world clinical practice, such as turn-by-turn dialogue, is in its early stages, but shows promise. A 2025 analysis of a large volume of simulated consultations conducted by Articulate Medical Intelligence Explorer (AMIE), a LLM-based system optimised for diagnostic dialogue developed by Google, demonstrated performance superior to human clinicians on a wide range of performance measures13. Communicating in an empathetic manner may not be limiting: early data suggests when shown text responses to medical question, patients tend to judge LLM-written responses as more empathetic than physicians’ responses.14 There is now a pressing need to cautiously extend LLM evaluations to a wide range of real world clinical situations, with all of the challenges that presents15: such work has only recently started16.
How good is good enough, and in which contexts?
The right criteria to measure conversational clinical AI remain uncertain,17 but will almost certainly need to be specific to the clinical task and context. Several approaches have been proposed, including making use of medical education evaluation frameworks like the MRCP PACES examination13. However, many rubrics rely heavily on the knowledge and judgement of the evaluator/examiner, with broad scoring criteria like “responded appropriately to patient concerns”. This method works for expert human examiners, who themselves have been benchmarked as part of their training, but more specificity is surely needed to meet the speed and scale of the development of clinical conversational AI.
Clinical conversational quality in AI should be judged in ways which are ecologically valid: an ability to build rapport with patients, extract the relevant information, manage the noise of real-world patient consultations, and provide reliable safety-netting when clinical boundaries are reached. To achieve this most rapidly, it makes sense to run digital simulations of consultations, using AI evaluators to judge the performance of the clinical AI. Here, we cannot assume that an AI evaluator will know what it means to “respond appropriately to patient concerns” in a given context.
New AI-appropriate quality evaluation rubrics are needed, which do not assume knowledge on the part of the examiner. A comprehensive rubric might include the content (covering the relevant questions) of a given patient interaction, the model’s conduct (the communication manner) and its wider context in the care pathway (eg. is there bias, does it respect ethical norms, are the financial and environmental costs appropriate). It is likely that a general clinical AI rubric will need to be paired with modular domain-specific rubrics, which should be paired with appropriate thresholds in quality sub-domains that represent a minimum acceptable standard for safety, in the planned deployment context.
Explainability, over-confidence and bias
Counterintuitively, for a human-developed technology whose underlying architecture we understand, many aspects of LLM performance are very opaque. This starts with model pre-training: for commercial reasons frontier laboratories often do not describe which data was used, nor are basic information like the number of parameters (let alone their actual values). Even where these are shared (e.g. in open-weights models), it remains unclear for what reason a given input produces a particular output: indeed, there is an entire field of mechanistic interpretability or ‘AI biology’ research, which seeks to understand LLM behaviour18,19.
While the knowledge and behaviour of LLMs is a source of much uncertainty to human users (often described as a ‘black box’), nor do the tools themselves appear to poses strong self-knowledge. Such meta-knowledge, “knowing what you don’t know”, is essential for safe clinical practice. While the abilities of models to attach meaningful confidence scores to their assertions in medical benchmark tests has improved over time, there are key limitations in this skill20. This is an important but often overlooked requirement, which, alongside the depth and breadth of clinical knowledge, will be key to determining the required amount of oversight.
The extent to which models are systematically wrong or ‘biased’, is also important for clinicians to understand. Recapitulating biases present in training data is a particular concern and has been well described. For example, tasked with recommending psychiatric treatments, LLMs have in research work recommend different treatments based on ethnicity, 21 or altered their behaviour due to patient wealth (recommending advanced imaging investigations), housing status and gender identiy.22 Mitigating these biases is a challenge. The possibility space of clinical context, user characteristics, and model outputs is extremely wide, bias may be present but difficult to identify, and models lack deep “moral underpinnings” governing behaviour.
Data protection
Patients and clinicians need complete confidence that their information is communicated and held securely. Appropriate security standards for health data already exist, and cloud compute providers like Amazon Web Services and Microsoft Azure offer UK based ‘sovereign’ server facilities meeting General Data Protection Regulations (GDPR) requirements for special category health data. Such systems handle large amounts of sensitive data, like the NHS-wide Microsoft 365 email suite.
Additional assurances are needed for language models specifically: we need to know whether patient data will be used to train future models, or fine-tune existing ones, because these data might then be stored in model weights and could thus be potentially extracted. Model providers currently allow users to opt out of training on their data. Clearly, this needs to be the default in healthcare contexts. A zero-trust option is to run open-weight models locally within a hospital’s IT infrastructure, without any data leaving the premises. This is attractive from a security perspective, it remains to be seen whether cost and hardware requirements to achieve this are prohibitive in practice.
Wider impact and integration
Consideration needs to be given to where conversational AI can genuinely add value within healthcare systems. This is likely to relate to how reliable LLM-based applications are in specific tasks, the riskiness of the context, and the degree of clinician oversight required.
The need for oversight is likely to be greatest initially and to reduce over time as evidence accumulates. We envision three phases. In the first, clinicians remain ‘in the loop’: for instance AI-drafted management plans or decision-support outputs which must be reviewed and approved by a human, who retains responsibility for diagnosis and prescribing. With appropriate evidence, systems may move towards a ‘clinician on the loop’ model, in which some system behaviour is automated within defined constraints, with human oversight and intervention where needed. In the longer term, it may become possible to design more autonomous clinical AI systems in which the clinician is ‘off the loop’, though this will require substantial evidence of safety and efficacy and careful consideration of clinical accountability frameworks.
Patient and clinician should not be assumed23. We need to ensure that tools are user-friendly and genuinely helpful for patients, who are often not involved health technology procurement, but nevertheless are required to interact with tools at moments of anxiety and vulnerability. Conversational clinical AI should therefore be co-developed with service users, whose involvement needs to span the entire development cycle, and extend into post-deployment monitoring.
It is important to note that current regulations governing medical devices, which include software, were not developed with language model-based systems in mind, and hence do not yet deal well with their complexities. EU, US and UK regulators are developing new rules to address this, whose content remains very uncertain, but is likely to include particular provision for updatability and long-term performance monitoring, to mitigate concerns about algorithmic drift, whereby accuracy can worsen over time if input data deviate more from training data24.
Conclusion
There is an important and new opportunity to develop conversational clinical AI tools that widen access to clinical reasoning support and offload routine information gathering to support, rather than replace, expert clinicians. This should not be done with a “move fast and break things” approach. Instead, urgent but careful development needs is needed by teams combining technical experts, clinical specialists, and the people who will use these services, targeting real-world clinical problems and rigorously evaluated prospectively.
Box. Historical Perspective
In the 1940s, McCulloch and Pitts conceptualised biological neurons as computational devices that integrate inputs and produce binary outputs, capable of implementing logical operations when used together in networks.25 Hebb’s observation that inter-neuronal connections are strengthened when activated together26 was important in developing artificial neural networks optimised to learn from experience. In the late 1950s Rosenblatt conceptualised a learning neural network (‘the perceptron’) in which input weights could be adjusted through a learning rule based on prediction error.27 However, single-layer networks cannot perform tasks requiring non-linear separation (e.g. XOR logic),28 a limitation that shifted some researchers toward symbolic, rule-driven approaches. One notable example was the ELIZA chatbot29, which simulated a Rogerian psychotherapist using pattern matching, but whose limitations quickly became apparent, falling far short of the benchmark for machine intelligence proposed by Turing 30.
Multi-layer architectures, enhanced by backpropagation31 enabled more complex computations. Recurrent neural networks (RNNs) and long short-term memory (LSTM) architectures32 improved models’ ability to handle sequential data and long-range dependencies. A further advance was the development of word embeddings (Word2Vec)33 which encoded words as numerical vectors capturing semantic relationships, enabling mathematical operations on language (e.g. King − Man + Woman ≈ Queen).
A critical breakthrough came in 2017 with the transformer architecture34: unlike prior architectures which processed words sequentially, now, every input word could be related to each and every other word, so-called ‘self-attention’, affording greater contextual understanding including long-range dependencies. This enabled the pre-training and fine-tuning paradigm, first seen in Google’s BERT model35 and OpenAI’s GPT-136, followed by rapid caling of LLMs including GPT-337, PaLM38, LLaMA39, GPT-440. More recently, models have incorporated chain-of-thought reasoning, tool use (such as web search), and retrieval-augmented generation (RAG) architectures providing rapid access to external knowledge bases such as clinical guidelines.
References
1. World Health Organisation. Health and care workforce in Europe: time to act. 2022. 14/09/2022. https://www.who.int/europe/publications/i/item/9789289058339
2. Association of British Neurologists. Neurology Workforce Survey (2018-2019). 2020;
3. Cabral S, Restrepo D, Kanjee Z, et al. Clinical Reasoning of a Generative Artificial Intelligence Model Compared With Physicians. JAMA Internal Medicine. 2024;184(5):581–583. doi:10.1001/jamainternmed.2024.0295
4. Liu X, Liu H, Yang G, et al. A generalist medical language model for disease diagnosis assistance. Nature Medicine. 2025/01/08 2025;doi:10.1038/s41591-024-03416-6
5. Clusmann J, Kolbinger FR, Muti HS, et al. The future landscape of large language models in medicine. Communications Medicine. 2023/10/10 2023;3(1):141. doi:10.1038/s43856-023-00370-1
6. Lees AJ. Reduced to a number. Practical Neurology. 2023;23(6):536. doi:10.1136/pn-2023-003803
7. Hatamnejad A, Higham A, Somani S, et al. Feasibility of an artificial intelligence phone call for postoperative care following cataract surgery in a diverse population: two phase prospective study protocol. BMJ Open Ophthalmology. 2024;9(1):e001475. doi:10.1136/bmjophth-2023-001475
8. Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models. arXiv preprint arXiv:200108361. 2020;
9. Smith AL, Greaves F, Panch T. Hallucination or Confabulation? Neuroanatomy as metaphor in Large Language Models. PLOS Digit Health. Nov 2023;2(11):e0000388. doi:10.1371/journal.pdig.0000388
10. Singhal K, Azizi S, Tu T, et al. Large language models encode clinical knowledge. Nature. Aug 2023;620(7972):172–180. doi:10.1038/s41586-023-06291-2
11. Gu Y, Fu J, Liu X, et al. The Illusion of Readiness in Health AI. arXiv preprint arXiv:250918234. 2025;
12. Han T, Adams LC, Bressem KK, Busch F, Nebelung S, Truhn D. Comparative Analysis of Multimodal Large Language Model Performance on Clinical Vignette Questions. JAMA. 2024;331(15):1320–1321. doi:10.1001/jama.2023.27861
13. Tu T, Schaekermann M, Palepu A, et al. Towards conversational diagnostic artificial intelligence. Nature. 2025/06/01 2025;642(8067):442–450. doi:10.1038/s41586-025-08866-7
14. Ayers JW, Poliak A, Dredze M, et al. Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. JAMA Intern Med. Jun 1 2023;183(6):589–596. doi:10.1001/jamainternmed.2023.1838
15. Azad TD, Krumholz HM, Saria S. Principles to guide clinical AI readiness and move from benchmarks to real-world evaluation. Nature Medicine. 2026/01/23 2026;doi:10.1038/s41591-025-04198-1
16. Brodeur P, Koshy JM, Palepu A, et al. A prospective clinical feasibility study of a conversational diagnostic AI in an ambulatory primary care clinic. arXiv preprint arXiv:260308448. 2026;
17. Lim E, Thirunavukarasu A, He YV, et al. Building a code of conduct for AI-driven clinical consultations. Nature Medicine. 2026/01/06 2026;doi:10.1038/s41591-025-04068-w
18. Templeton A, Conerly T, Marcus J, et al. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet. Anthropic. Updated 2024–05–21. https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
19. Lindsey J, Gurnee W, Ameisen E, et al. On the Biology of a Large Language Model. Anthropic. Updated 2025–03–27. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
20. Griot M, Hemptinne C, Vanderdonckt J, Yuksel D. Large Language Models lack essential metacognition for reliable medical reasoning. Nature Communications. 2025/01/14 2025;16(1):642. doi:10.1038/s41467-024-55628-6
21. Bouguettaya A, Stuart EM, Aboujaoude E. Racial bias in AI-mediated psychiatric diagnosis and treatment: a qualitative comparison of four large language models. NPJ Digit Med. Jun 4 2025;8(1):332. doi:10.1038/s41746-025-01746-4
22. Omar M, Soffer S, Agbareia R, et al. Sociodemographic biases in medical decision making by large language models. Nat Med. Jun 2025;31(6):1873–1881. doi:10.1038/s41591-025-03626-6
23. Busch F, Hoffmann L, Xu L, et al. Multinational Attitudes Toward AI in Health Care and Diagnostics Among Hospital Patients. JAMA Network Open. 2025;8(6):e2514452–e2514452. doi:10.1001/jamanetworkopen.2025.14452
24. Graham N, Zimmerman K, Hain JA, et al. Midlife Plasma Proteomic Profiles Indicate Altered Amyloid and Tau Processing in Former Elite Rugby Players. JNNP. 2025;
25. Mcculloch W, Pitts W. A Logical Calculus of Ideas Immanent in Nervous Activity. Bulletin of Mathematical Biophysics. 1943;5:127––147.
26. Hebb DOT. The organization of behavior. Wiley; 1949.
27. Rosenblatt F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review. 1958;65(6):386–408. doi:10.1037/h0042519
28. Minsky M, Papert S. Perceptrons: An Introduction to Computational Geometry. MIT Press; 1969.
29. Weizenbaum J. ELIZA—a computer program for the study of natural language communication between man and machine. Commun ACM. 1966;9(1):36–45. doi:10.1145/365153.365168
30. Turing AM. I.—COMPUTING MACHINERY AND INTELLIGENCE. Mind. 1950;LIX(236):433–460. doi:10.1093/mind/LIX.236.433
31. Rumelhart DE, Hinton GE, Williams RJ. Learning representations by back-propagating errors. Nature. 1986/10/01 1986;323(6088):533–536. doi:10.1038/323533a0
32. Hochreiter S, Schmidhuber J. Long Short-Term Memory. Neural Computation. 1997;9(8):1735–1780. doi:10.1162/neco.1997.9.8.1735
33. Mikolov T, Chen K, Corrado G, Dean J. Efficient estimation of word representations in vector space. arXiv preprint arXiv:13013781. 2013;
34. Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Advances in neural information processing systems. 2017;30
35. Devlin J, Chang M-W, Lee K, Toutanova K. Bert: Pre-training of deep bidirectional transformers for language understanding. 2019:4171–4186.
36. Radford A, Narasimhan K, Salimans T, Sutskever I. Improving language understanding by generative pre-training. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
37. Brown T, Mann B, Ryder N, et al. Language models are few-shot learners. Advances in neural information processing systems. 2020;33:1877–1901.
38. Chowdhery A, Narang S, Devlin J, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research. 2023;24(240):1–113.
39. Touvron H, Lavril T, Izacard G, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:230213971. 2023;
40. Achiam J, Adler S, Agarwal S, et al. Gpt-4 technical report. arXiv preprint arXiv:230308774. 2023;